

It is said, in North Korea, children are taught that their loving ex-leader Kim Jong Il did not even have to urinate because he was so pure. No excrement generated in his body due to his super-human purity. As a software engineer I think that most of our code behaves also like Kim Jong Il. Our code is ultra pure so that it surpasses every contingency in general human discourse occurring due to imprecision and vagueness. For instance, the statement start_time = 3 in a computer program literally means it while in human conversation “The event starts at 3” does not imply a rigid spontaneity. In a statement like the latter, we humans implicitly agree that the start time can fall within an acceptable time window centered around 3. In any society, a deviation of few seconds will be accepted. However, the program would not accept 3.0001 or 2.998.
This behavior with programs generally works. If you are developing accounting software, you probably don’t want to jeopardize your program logic with vagueness in human thinking. In fact lot of practices are involved in software delivery (such as manual testing, unit testing and code quality analysis) to cut the crap introduced by humanness and make the software as pure as Kim Jong Il. However, there are cases that a programmer is left with no other option but to stretch boundaries of his thinking a little further than the psychotic notion of purity and to get along with the real world while encountering its inevitable vagueness. Following is an example from a recent programming experience of mine.

Recently we implemented an iPad navigation app for a leading Norwegian GIS (Geographic Information Systems) company. The app is intended to help people when going on boat rides by providing specialized maps. In addition to this main purpose it is bundled with lot of other useful features such as path tracking, geo-fencing, geo-coding, social media sharing, etc.
Not surprisingly the app needs to determine user’s current location to enable most of its features. For this, we employed location services API that ships with iOS. It uses various sources such as GPS, access tower data and crowd-sourced location data when determining the geo-coordinates of the device location. Each of these location sources has different implications on accuracy and battery consumption. For instance, GPS is by far the most accurate method, but drains the battery faster. On the other hand, wifi iPads that amount to a significant fraction of the iPads that are currently in use, do not have GPS receivers. The only accessible location information for them comes from crowd sourced location data from wifi hot spots that agree to share their location. Inevitably these location coordinates are less reliable. One nice thing with iOS location API is that, along with every location coordinate it also provides information on how accurate (or how inaccurate) the reading can be. This is called the tolerance value. For example, when we see a location coordinate (in the form latitude – longitude) 35.45o, 4.87o with tolerance 20 meters, we know that the user’s actual location can be anywhere inside a circle of radius 20 meters centered at the point (35.45o, 4.87o). With our experiments we figured out that when GPS is used to determine the location, tolerance level is as low as 5 meters. However, with wifi iPads, the best we observed was 65 meters. To make things more complicated, even the iPads with GPS receivers, at times, can go low down in accuracy (with tolerance levels as high as several hundreds of meters). This particularly happens when the device is in the vicinity of objects like huge concrete structures or large trees that effectively blocks GPS signals.
Need to determine location accuracy mode
Experimentation clearly suggested that there are two disparate modes that an iPad can be operating at a given moment with respect to location detection; high accuracy mode and low accuracy mode. These two modes are characterized by the following behaviors.
| High Accuracy Mode (HAM) | Low Accuracy Mode (LAM) |
| Tolerance value is low for most location readings | Tolerance value is high for most readings |
| Location readings are received in regular intervals (can be as frequent as once in a second) | Location readings are received less frequently (usually only few times in a minute) |
When in high accuracy mode we can treat received location coordinates as the actual location. In addition we can happily ignore intermittent low accuracy readings (readings with high tolerance values – these can occur even in high accuracy mode occasionally). In contrast, the programmer has to make every attempt to use all acceptable readings (readings without crazily high tolerance, such as more than 1 km) when in low accuracy mode since only few location readings are typically received during 1 minute. Also, corrections may need to be applied (depending on the purpose) since the accuracy level is low. Because the developer has to apply two kinds of logics depending on the accuracy mode, it’s necessary to determine the mode that the device is operating at a given moment. One should also note that the mode could change with time; for instance, when a person is moving with a GPS iPad, the device can be operating in high accuracy mode mostly, but can also switch to low accuracy mode when it is close to a big building.
Difficulty in drawing the line between two modes
The first (and probably the toughest) challenge is to correctly figure out whether the device is operating in HAM or LAM. It doesn’t take much thinking to identify that one can use both tolerance value and location reading frequency to determine the mode. If most tolerance values are low and the device is receiving location readings in regular intervals, it should be in high accuracy mode. However, formulating the logic is not as simple as it sounds because it needs explicit manifestation of numeric boundaries between the two modes. For example, let’s say that we decide to conclude the operating mode as HAM when the best tolerance is less than 20 meters and 15 readings or more are received within a period of 30 seconds. It’s not difficult to illustrate the problem associated with this approach. Consider the following 3 cases.
Case 1: Best tolerance is 18 meters and 15 readings are received within 30 seconds.
Case 2: Best tolerance is 21 meters and 15 readings are received within 30 seconds.
Case 3: Best tolerance is 18 meters and 13 readings are received within 30 seconds.
Intuition suggests that most probably the device should have been operating in the same mode in all 3 cases. However, our previous logic with stubborn numeric boundaries results in case 1 being identified as high accuracy mode, while the other two being recognized as low accuracy. Can you see the problem here? The problem is not about using numeric boundaries (we have to do that as long as we program for a Von Neumann computer). However, the problem lies in selection of the numeric boundary. What justifies selection of 20 meters as the tolerance boundary? Similarly, how confident are we, that the frequency boundary should be 15? A sufficient probe into the problem would reveal that it’s almost impossible to develop a sound heuristic that determines these boundary values “accurately”.
Where exactly is the problem?
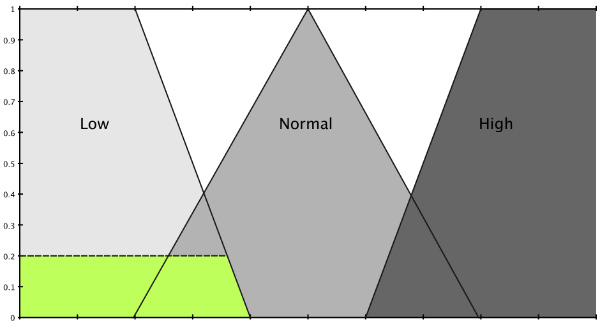
The problem really lies on the discrepancy between skills of humans and computers. Humans are clever in dealing with concepts than with numbers while computers are better in handling numbers. This is evident in that we could distinguish between the two modes easily when we were talking in terms of concepts (to reiterate our previous statement -> ‘If most tolerance values are low and the device is receiving location readings in regular intervals, it should be in high accuracy mode’). The moment we try to put this logic in terms of numbers, we run into chaos. This is a clear case where ‘pure logic’ leaves us in a desperate abyss.
Await Part 2…
Await Part 2 of this article where we explore how fuzzy logic brings in the solution to this problem.
Dileepa, Welcome to TechWire!
[…] Like it Note from the editor: This is the last of the two-part article series on how real world problems can be solved using fuzzy logic. Part I of this article can be found here. […]