The ZeroTurnAround team took attention in the Java developer community with the Java EE Productivity Report back in 2011. It mainly focused on tools, technologies and standards in use and general turnaround time in development activities based on Java as a language. They have comeback this year with their latest survey on Java developer productivity which uncovers very interesting trends about the practical aspects Java development lifecycle.
In their report, they discuss tools and technology usage as well as findings on developer time usage, patterns in efficiency and factors which govern developer stress in general. In Part I of this article, we discussed tools and technology usage findings. Part II discusses the developer timesheet, efficiency and stress based on the survey results of Java developers. Also there are a few interesting Q&A sessions that they had with a few well known geeks in the industry.
Developer timesheet
In their survey on what JAVA developers spend their day at work, they found 3 very interesting points:
1. Developers only spend about 3 hours per day writing code
2. Developers spend more time in non-development activities than we expect them to. For each hour of coding that they do, half an hour is spent on activities such as meetings, reporting and writing emails etc.
3. Developers spend more time firefighting than building solutions
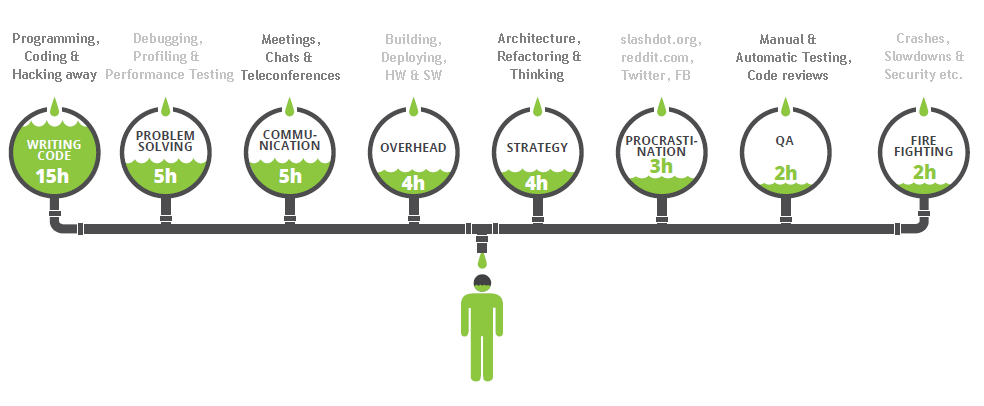
Following is the work breakdown that they’ve found with the activities under each group. Note that “Writing code” is not the same as “Coding” which is generally used to identify writing code, problem solving, QA and strategy altogether.
Here is an extract from the interview with Linconln Baxter III about the findings. Linconln is a Senior Software Engineer at Red Hat (JBoss Forge), founder of OCPSoft, and open source author/advocate/speaker.

[quote_simple]
ZT: What do you think about finding number 1: developers spend less time writing code than you think? It’s just 3 hours per day it seems.
LBIII: I’m not surprised one bit. The biggest drain on productivity is the constant interruptions to our concentration; that can be co-workers, running a build, running tests to check your work, meetings; it can take up to 25 minutes to regain your focus once you’ve been distracted from your original task.
Think of a brain as if it were a computer. There is waste every time a computer shifts from one activity to another (called a context switch), a very expensive operation. But computers are better at this than we are because once the switch is complete they can immediately resume where they left off; we are not so efficient.
When considering context switching, builds and everything else considered “Overhead” are the biggest distractions from writing code. Even though this piece of the pie is only responsible for 4.63 hours of a developer’s week, in reality, the true impact of this problem is much greater. Once you add in all the other distractions of the workplace, I’m impressed anyone gets work done at all. Every re-deployment is going to cost you an extra 25 minutes of wasted focus, in addition to the deployment cost itself.
[/quote_simple]

Developer Efficiency
This is what developers think what makes their life inefficient at their work places. It’s not the manager’s view; it’s not the independent consultants view. So there should be something to take from it for all of us.
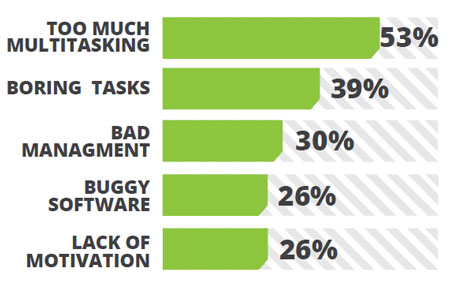
Majority of the developers think too much multitasking create inefficiency. This is somewhat highlighted in the interview with Linconln Baxter. According to him, each context switch will cause 25 minutes of recovery time before the next task to be productive. No wonder too much multitasking will do to the developers. They will simply be switching between tasks without any of them getting completed. From the today’s organizational environments, it’s mandatory that we all multitask in order for us to achieve better and more efficiently. This simply suggests that we should find the right balance when it comes to software development.
Boring tasks are also identified as promoting under-efficiency. There are debates whether the boring tasks should be completed as soon as possible without letting it make your day dull.
Bad management of own time and work as a whole, having buggy software to start with and lack of motivation to do the job have established once again as common problems in causes of inefficiency.
ZeroTurnAround team has interviewed Matt Raible who has few interesting ideas why the statistics makes sense with his real life experience. Matt is a Web architecture consultant, frequent speaker and father with a passion for skiing, mountain biking and good beer.
[quote_simple]
ZT: What can you say about “Bad Management”?
MR: Yeah, what works great for me is to get used to non-standard work hours, and avoiding inefficient wastes of time.
Work long hours on Monday and Tuesday. This especially applies if you’re a contractor. If you can only bill 40 hours per week, working 12-14 hours on Monday can get you an early departure on Friday. Furthermore, by staying late early in the week, you’ll get your productivity ball rolling early. I’ve often heard the most productive work day in a week is Wednesday.
Avoid meetings at all costs. Find a way to walk out of meetings that are unproductive, don’t concern you, or spiral in to two co-workers bitching at each other. While meetings in general are waste of time, some are worse than others. Establish your policy of walking out early on and folks will respect you have stuff to do. Of course, if you aren’t a noticeably productive individual, walking out of a meeting can be perceived as simply “not a team player”, which isn’t a good idea.
ZT: Lack of motivation was cited as another factor preventing developers from being more efficient. Any thoughts on that?
MR: Look, you have to work on something you’re passionate about. If you don’t like what you’re doing for a living, quit. Find a new job ASAP. It’s not about the money, it’s all about happiness. Of course, the best balance is both. It’s unlikely you’ll ever realize this until you have a job that sucks, but pays well. I think one of the most important catalysts for productivity is to be happy at your job. If you’re not happy at work, it’s unlikely you’re going to be inspired to be a more efficient person. Furthermore, if you like what you do, it’s not really “work” is it?
[/quote_simple]
Developer Stress
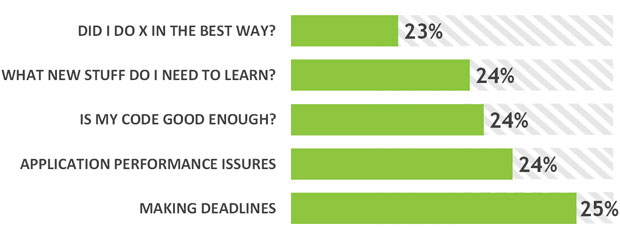
Among the answers to the question “what keeps you up at night?” many say “nothing, I sleep like a baby”. But there are following 5 stressors at the top of the problems which usually keeps developers up at night.
It looks like developers are more concerned about the accuracy, completeness and quality of their code. Whether they are competitive in the world’s fastest running industry. Although not by a large margin the most popular stressor “Making deadlines” also there with one out of every four developers are stressed up due to making deadlines. External reasons like software estimation problems and interruptions as well as not managing one’s work can cause working extra hours in catching deadlines.
In the interview with Martijn Verburg, ZeroTurnAround team gets exposed to a set of useful points each developer should know and adhere to make their lives stress free; at least from the work stress!
Martijn is also known as “The diabolical Developer”, Java community leader, speaker and CTO at TeamSparq.
[quote_simple]
ZT: I was surprised to see that developers are primarily concerned about Making Deadlines. Isn’t that something that The Suits should be worrying about more?
MV: Managing deadlines is something that a lot of developers feel that they cannot learn or is out of their control (e.g. their manager tells them what the deadline is). However, managing deadlines is a skill that can definitely be learned! For example, developers can learn to:
- Scope work into manageable (1day chunks)
- Define what “DONE” means (95% is not DONE)
- Factor in contingencies
- Communicate risks and issue to stakeholders
- Learn to prototype ideas to keep the overall project flowing
There are a number of tools to assist you in managing the scope and communication around deadlines, but always remember, “Whatever they tell you, it’s a people problem” so developers should look at their communication and expectation setting first.
ZT: Next, why do you think Performance Issues would rank so highly on the list of developer stress?
MV: Performance and performance tuning is terrifying for most developers because they have no idea where to start. Modern software applications are so complex that it can feel like finding a needle in a haystack. However, performance and performance tuning is actually a “SCIENCE”, not an art and definitely not guesswork. Krik Pepperdine (one of Java’s foremost expert in this field) always hammers home the point “Measure, don’t guess”.
By following the sort of scientific methodology that Kirk and others like him teach, you can systematically track down and fix performance issues as well as learning to bake performance in right from the beginning. There is a host of tooling that can assist in this area as well, but it’s the methodology that’s truly important. I can highly recommend Kirk’s course (www.kodewerk.com – he runs courses worldwide, not just in Crete, so drop him a line).
[/quote_simple]













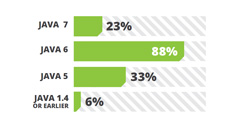
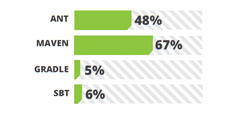
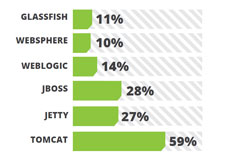 Apache Tomcat remains the most widely used open source application server. JBoss and Jetty is securing their place in the community. First released in October 2011, Jetty looks very attractive to the developer community with its lightweight and cool enterprise level features. It supports Servlet 3.0 and has better easy to follow documentation which is a major plus point that attracted developers. Being the giant’s choice Weblogic and WebSpehere are there with more and more features added to the list as well as improved setting up capabilities. For example, Weblogic 12c promised 200 new features and it can be distributed as a zip archive. That means there is no time consuming installers; just unzip and run!
Apache Tomcat remains the most widely used open source application server. JBoss and Jetty is securing their place in the community. First released in October 2011, Jetty looks very attractive to the developer community with its lightweight and cool enterprise level features. It supports Servlet 3.0 and has better easy to follow documentation which is a major plus point that attracted developers. Being the giant’s choice Weblogic and WebSpehere are there with more and more features added to the list as well as improved setting up capabilities. For example, Weblogic 12c promised 200 new features and it can be distributed as a zip archive. That means there is no time consuming installers; just unzip and run!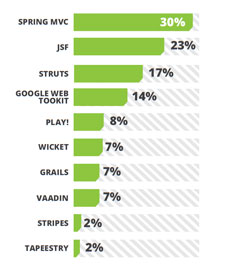 While Spring MVC, JSF, Struts and GWT have consistent market share against last year survey results, GWT (Google Web Toolkit) has gained some market share compared to the others.
While Spring MVC, JSF, Struts and GWT have consistent market share against last year survey results, GWT (Google Web Toolkit) has gained some market share compared to the others. 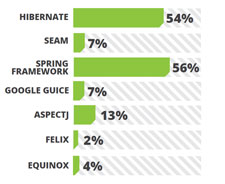
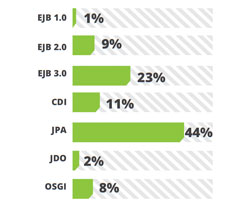 Java Enterprise Edition’s light weight contenders JPA, EJB 3.0 and CDI has enjoyed wider acceptance in the last year as well. Supported well by Hibernate and EclipseLink, JPA remains at the top scoring a 44%.
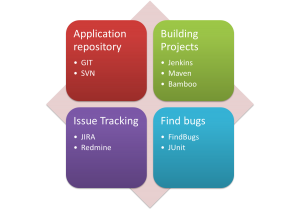
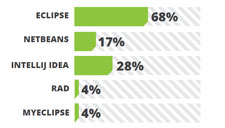
Java Enterprise Edition’s light weight contenders JPA, EJB 3.0 and CDI has enjoyed wider acceptance in the last year as well. Supported well by Hibernate and EclipseLink, JPA remains at the top scoring a 44%.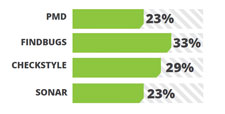 PMD and FindBugs are static analysis tools where CheckStyles checks for code styling according to the standard and readability of your code. Sonar provides a suit of code quality tools. FindBugs operate on Java byte code rather than the original source code and analyzes for possible problems that can cause trouble if not fixed before releasing. It is a project from the University of Maryland and has plugins available for Eclipse, NetBeans and Intelli JIDEA.
PMD and FindBugs are static analysis tools where CheckStyles checks for code styling according to the standard and readability of your code. Sonar provides a suit of code quality tools. FindBugs operate on Java byte code rather than the original source code and analyzes for possible problems that can cause trouble if not fixed before releasing. It is a project from the University of Maryland and has plugins available for Eclipse, NetBeans and Intelli JIDEA.{kind=link}
{kind=link}
{kind=link}